University of Florida
Aug 2022 – Expected Aug 2026Ph.D. in Agricultural and Biological Engineering · GPA: 3.95/4.0
I work on data infrastructure that allows agricultural files to remain verifiable after they cross organizational boundaries.
The healthcare industry addressed a version of this problem with shared ledger-based record coordination, and the finance industry addressed it with append-only audit trails. The agriculture industry has neither. Once a file moves between organizations, the receiving party cannot verify whether it matches what was originally recorded, because the originating system may be inaccessible and no shared reference survives the transfer.
Over four years, I built DEMETER, a platform that lets organizations share data while keeping a verifiable, traceable record that no single party controls. As a result, a receiving party can verify a file's origin and transformation history without contacting any earlier organization — a check that was previously impossible. The independent research behind each layer follows: who registered the file, what was done to it, and how it was shared.
My earlier work on vision systems for marine aquaculture at Billion21 was where I learned this firsthand: production environments, not benchmarks.
The same principle guides all of it: the key challenge is not applying the newest method, but building systems that work reliably where it matters.
| Backend & Distributed | Hyperledger Fabric, Go, Node.js, Express, REST APIs, gRPC, microservices |
| Data & Pipelines | Apache Airflow, Apache Spark, Apache Kafka, data lineage, ETL, PostgreSQL, MongoDB, CouchDB, Firebase |
| Cloud & DevOps | AWS, Azure, Docker, Kubernetes, CI/CD (GitHub Actions), Git, Linux |
| Applied AI & Vision | LLM integration, agentic systems, prompt engineering, evaluation frameworks, PyTorch, YOLO, SAM, OpenCV |
| Frontend | Next.js, React, TypeScript |
| Languages | Python, Go, JavaScript, Java, C, C++, R, Rust |
Ph.D. in Agricultural and Biological Engineering · GPA: 3.95/4.0
B.S. in Computer Science, Minor in Mathematics · GPA: 3.8/4.0
University of Florida · Agricultural and Biological Engineering
Ministry of Agriculture, Food and Rural Affairs (MAFRA), South Korea
Delivered a comparative analysis of crop mechanization and digital-agriculture adoption between South Korea and the United States, used for cross-country technology and policy benchmarking.
Billion21
Global BioAg Linkages
Evaluated AI technology fit for agricultural production systems end-to-end, from technical feasibility and data-requirement scoping to market viability analysis, producing deployment recommendations for downstream pilot projects.
Texas Tech University
Developed computer-vision models for biological specimen detection and classification (plant species, animal behavior, acoustic signals), and built data analysis and visualization pipelines to interpret detection outputs across research datasets.
Each project below addresses a layer of the same problem: making agricultural data verifiable across organizational boundaries. The order moves from the integrated platform (DEMETER), to its independent infrastructure layers (DV, TI, SI), to the foundational research and field studies that motivated them.
A certifier receiving a dataset from a third-party lab has no way to verify whether the file matches what the originating organization recorded — the originating system may be inaccessible, and no shared reference connects the origin state to the copy in hand.
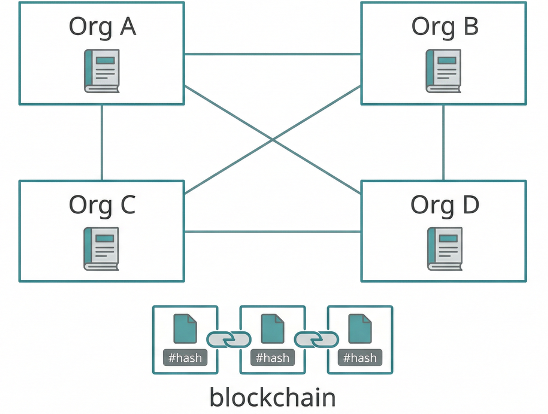
DEMETER records file history on a shared blockchain while files remain on each organization's local system. Three layers handle what is lost when files cross boundaries: where a file came from (origin), how it was changed (transformation), and how it was shared (integration). A natural language interface lets users query and write records through plain-text commands.
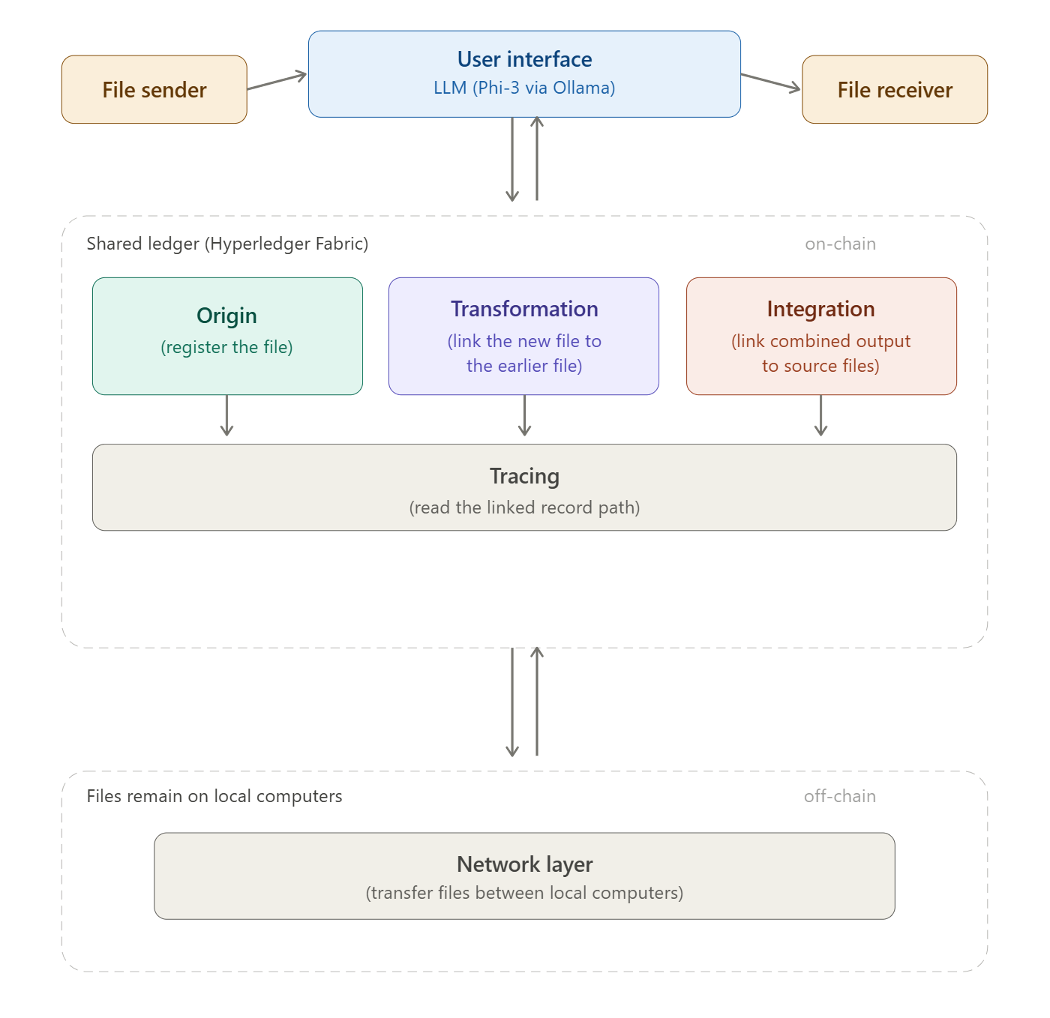
| On-chain | Go smart contracts on Hyperledger Fabric (Dataset, Transform, Reuse) |
| Backend | Node.js/Express REST API service layer |
| Frontend | Next.js + TypeScript with React Flow for provenance graphs |
| NLQ | Local LLM (Phi-3 via Ollama) with deterministic routing and a write-confirmation gate |
| Identity | DID-based login with browser-side key generation |
| Pipelines | Airflow orchestration, Kafka event streams, Spark batch aggregation over ledger history |
| Deployment | Four-organization Docker Compose test network with CI-driven build and test |
The platform was tested across four independently operated organizations and verified end-to-end. A receiving party can verify a file's origin, follow it through any transformations or combined outputs, and detect modifications — without contacting any earlier party. Provenance traces across 8,000 linked records resolve in under five seconds.

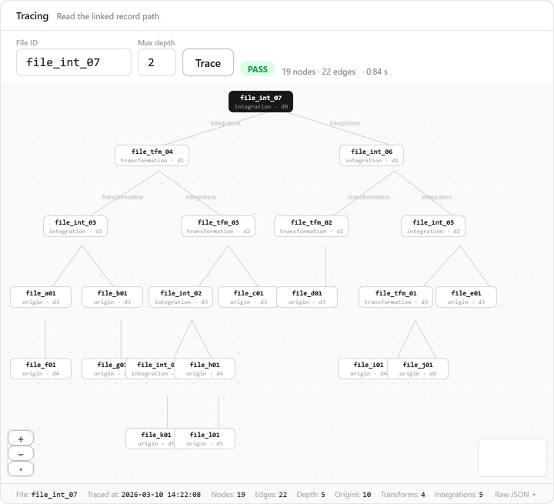
As a general-purpose bottom layer, DEMETER is currently being extended to soil spectrum and mapping data, fresh food to waste management, and smart aquaculture with edge computing. Future work includes pagination-based tracing beyond 8,000 records and AI agent interfaces for automated verification workflows.
Code: github.com/WhoisHOO/DEMETER (private during review, will be open-sourced upon publication)
Sourced by: Cho, Y., Yu, Z., & Ampatzidis, Y. DEMETER: An infrastructure for verification-traceable reuse of agricultural data across decentralized environments. Under review.
Users of a blockchain-based data system should not have to learn API endpoints or command syntax. At the same time, agricultural data sharing does not require deep reasoning from an LLM — it requires accurate intent classification and correct routing to the right operation.
The interface classifies user input into a fixed set of operations and routes each one to the correct DEMETER endpoint. Deterministic keyword matching handles the known patterns; an LLM (Phi-3 via Ollama) handles the rest, running locally with no external API dependency.
A write-confirmation gate sits in front of every operation that changes ledger state: the AI layer cannot modify anything without explicit user approval. This means the correctness of the verification infrastructure does not depend on LLM reliability — even an inaccurate model cannot silently corrupt the ledger.
When citrus drone TIFF imagery is repeatedly transformed for NDVI analysis, yield estimation, and disease monitoring, the receiving party cannot follow the chain back to the original capture. Existing blockchain frameworks store a new hash on-chain for every transformation, which fragments the trace and balloons storage costs as image volume grows.
This scalable traceability framework applies DV-TI infrastructure to citrus drone imagery from Immokalee, FL. Instead of logging every transformation as a new on-chain entry, a dynamic hashing ID mechanism updates when data is transformed, maintaining continuous traceability while reducing storage overhead. IPFS handles large file storage off-chain; the blockchain stores only IDs and metadata.
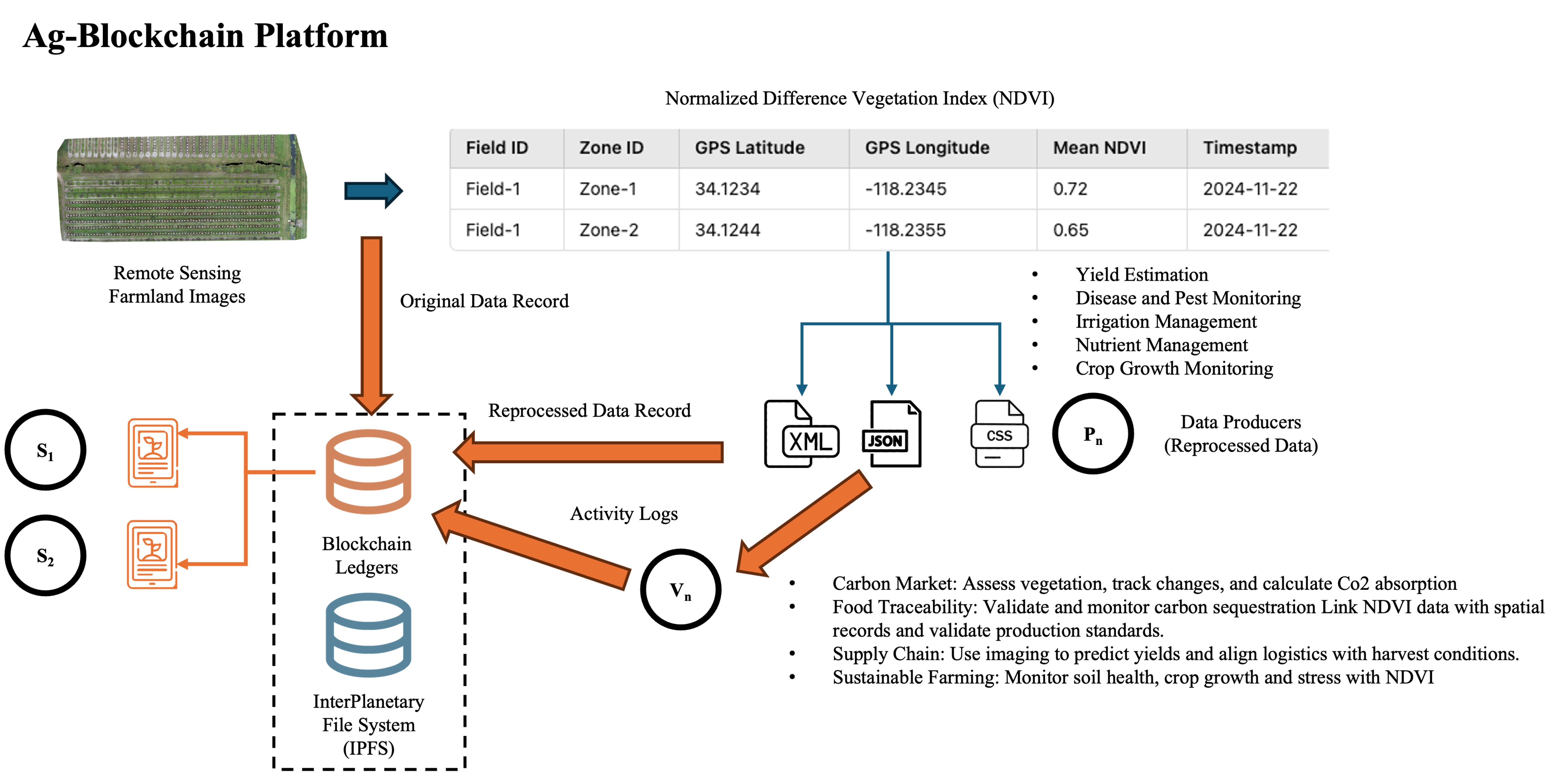
The smart contract logs every data interaction — uploads, access requests, transformations, downloads, and usage events — and each interaction generates a unique hashing ID that improves transaction speed and prevents redundant on-chain storage. Testing applied predefined criteria (data type, size, timestamp, geolocation) on citrus farm imagery.
All user activities were successfully recorded on-chain, with timestamps, user IDs, and access roles converted into secure hash values. The hashing ID update mechanism significantly reduced redundant storage compared to conventional blockchain-IPFS models, confirming that the system handles real-world scalability demands while preserving data integrity.
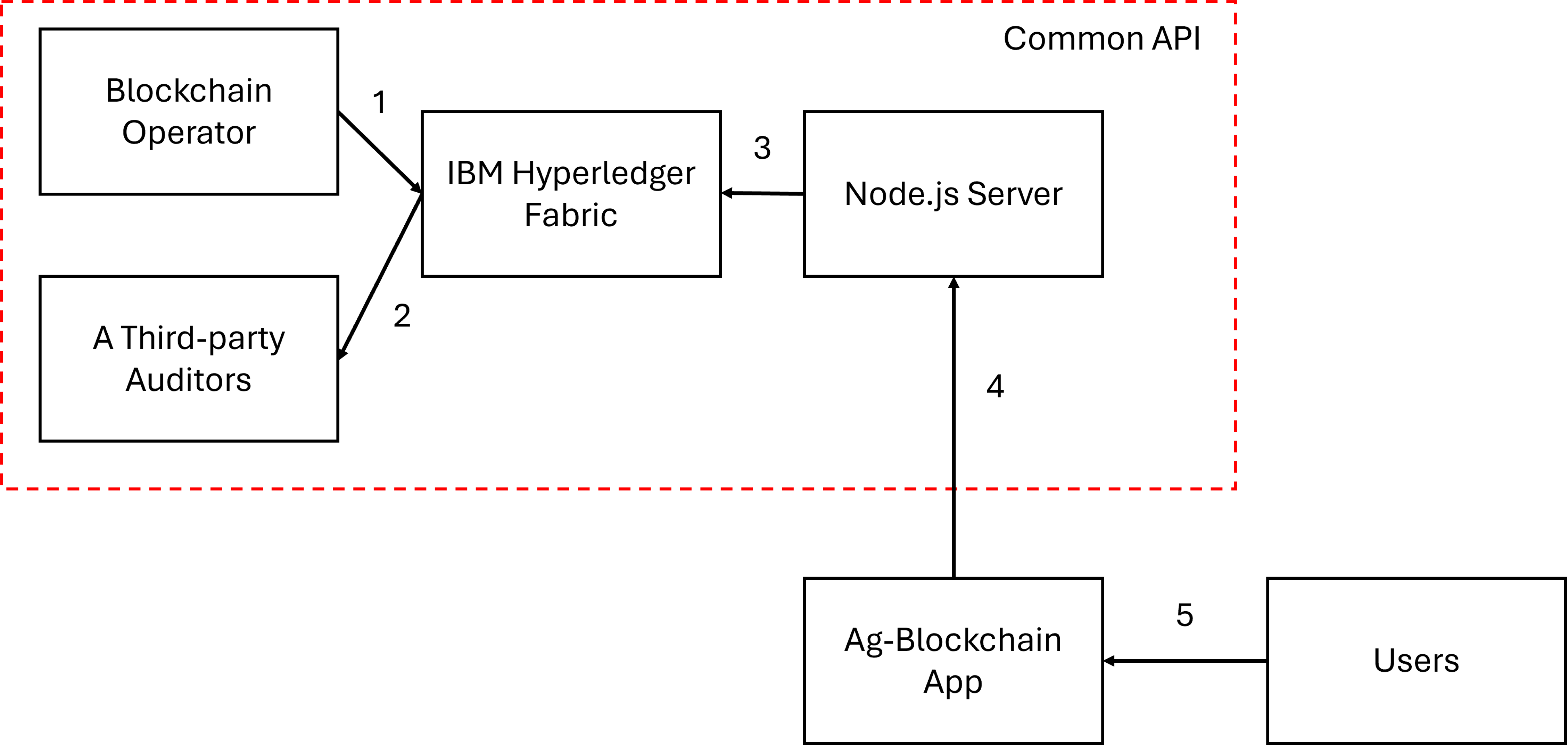
Future directions include a shared Ag-Blockchain API to enable data transformation and interoperability across farm management, food traceability, and sustainability applications, along with Zero-Knowledge Proofs (ZKP) to verify and track off-chain data modifications while preserving privacy.
When multiple files from different organizations are combined into a single output, the receiving party cannot determine which source files contributed or under what license conditions they were shared.
This infrastructure governs how files move between organizations and how combined outputs relate back to their sources, recording every access request, approval, transfer, and reuse decision on-chain.
The access request workflow runs through Request, Approve, Fulfill, and Download. Each stage produces an on-chain record so that any party can reconstruct who approved which transfer and under which license, without relying on any single party's internal logs. Reuse evaluation checks purpose against 7 Creative Commons license types with expiration enforcement and derivative restrictions. A decision chain tracing audits who approved what and when.
Code: github.com/WhoisHOO/demeter-si-infrastructure (private during review, will be open-sourced upon publication)
Sourced by: Cho, Y., Yu, Z., & Ampatzidis, Y. Under review.
When a file is transformed into a new file (e.g., raw sensor data into a loss appraisal), the new file has different content and a different fingerprint. The receiving party cannot determine which input was used or what operation was performed, because that information exists only inside the producing party's system.
This infrastructure lets a receiving party determine the declared registered input and declared operation for a transformed file using only the shared ledger, without contacting the producing environment.
The processor writes a declaration to the ledger linking input File ID to output File ID with an operation label, and declarations referencing unregistered inputs are rejected. Inspection follows the chain backward and returns one of three states: resolved, resolved with gap, or no declaration.
Importantly, TI verifies the consistency of a transformation declaration, not the correctness of the transformation process itself. Correctness verification would require re-executing the transformation, which is outside what a shared ledger can enforce. This boundary keeps infrastructure-level claims honest.
Validation used a two-stage chain (farmer registers, ATP-A transforms, ATP-B transforms again). The receiving party retrieves the full chain in one query, and declaration-time validation correctly rejects unregistered inputs.
Code: github.com/WhoisHOO/demeter-ti-infrastructure (private during review, will be open-sourced upon publication)
Sourced by: Cho, Y., Yu, Z., & Ampatzidis, Y. An Infrastructure for Determining the Declared Registered Input and Operation for a Transformed Agricultural File. Under review.
When a farmer sends a file to an intermediate party and that party forwards it to a receiving party, the receiving party has no way to check whether the file matches what the farmer originally recorded. The originating organization's system may be inaccessible, and no shared record connects the origin state to the copy in hand.
This infrastructure lets any receiving party verify whether a file has the same content as the version recorded before the first transfer, and reconstruct the full sequence of senders and receivers, without contacting any earlier computer.
A SHA-256 fingerprint is computed at registration and stored on the shared ledger, and each transfer is recorded as a linked entry. Verification recomputes the fingerprint from the file in hand and compares it against the ledger, while transfer tracing follows linked records backward to the origin.
Verification was confirmed across multi-hop transfers: modified files correctly fail verification (different fingerprint, no matching record), and tracing reconstructs the full path regardless of whether intermediate parties are online. This means a regulator receiving data three hops downstream can independently verify file integrity without any prior party being online.
Code: github.com/WhoisHOO/demeter-dv-infrastructure (private during review, will be open-sourced upon publication)
Sourced by: Cho, Y., Yu, Z., & Ampatzidis, Y. An Infrastructure for Agricultural File Origin Verification and Transfer Tracing. Under review.
Across agriculture, healthcare, and finance, blockchain has been applied to data sharing in fundamentally different ways. The agricultural blockchain literature often conflates two distinct things: supply-chain traceability, which tracks products, and data-file traceability, which tracks the origin, transfer, and transformation of data objects. Distinguishing them defined the scope of what verification infrastructure must do.
Agriculture had partial origin verification but no transformation or integration traceability. Healthcare and finance operate under mandatory regulatory frameworks (HITECH, SEC reporting) that compelled infrastructure investment. Agriculture has no equivalent mandate, which is why the gap persists. Healthcare had implemented origin, and finance had implemented origin and transformation. No sector had all three. Each missing layer maps to a distinct operational failure: without origin verification, a receiving party cannot confirm the file is unmodified; without transformation traceability, a derived output cannot be traced to its input; without integration traceability, a combined file cannot be decomposed to its sources. DV, TI, and SI address each failure independently.
Sourced by: Cho, Y., Yu, Z., & Ampatzidis, Y. Facilitating a Future Agricultural Data Ecosystem. Under review.
Seaweed (laver) farming in South Korea involves spore cultivation, harvesting, processing, and distribution across multiple independent parties. Each stage produces its own data — spore density readings at cultivation, harvest yield at recovery, processing conditions and batch records at the mill, and distribution paths between wholesalers and retailers — yet no shared system connects producers, processors, and distributors. Once a product leaves one party's system, the data needed for quality assurance and regulatory compliance is lost.
This blockchain-based data management system records production data, processing events, and distribution transfers on a shared ledger so that any receiving party can trace the full history of a seaweed product from spore cultivation through final delivery. Applying blockchain at this layer guarantees three properties the supply chain previously lacked: diversity across participating parties, security against tampering, and transparency for auditors and regulators.
The system builds directly on the laver spore selection patent (KR102034354B1), which established automated image-based quality assessment at the cultivation stage. Spore density judgments produced by that imaging pipeline become the first verifiable record on the ledger, and each downstream stage (harvest, processing, distribution) appends linked records referencing that origin.
Patent Application KR10-2024-0011399, 2024. Status: Pending.
Building data infrastructure for agriculture requires understanding what the data looks like. Modern agricultural machinery generates field data with specific characteristics, formats, and constraints that vary by crop and region.
These comparative studies of mechanization and cultivation patterns between the US and South Korea analyzed potato, sweet potato, and Chinese cabbage, examining how machinery data is produced, structured, and used in practice across different farming systems.
Sourced by: Kim, J.H., Cho, Y., et al. (2024–2025). Journal of Biosystems Engineering. 3 papers.
Carbon credits, insurance indemnity, and compliance decisions all depend on data that crosses organizational boundaries. If the receiving party cannot verify where the data came from, the decision rests on unverifiable claims.
This comparative study of stakeholder engagement in carbon markets between South Korea and the United States established why a data sharing perspective is necessary in agriculture and where verifiable infrastructure is missing.
Sourced by: Cho, Y., Yu, Z., & Ampatzidis, Y. (2025). Discover Agriculture, 3, 126.
Computer vision and machine learning projects across aquaculture and crop production. The first two shipped into real production systems and led to filed patents; the rest demonstrate applied skill across detection, classification, and recognition tasks.
Marine fish farms rely on manual observation for feeding decisions and growth assessment. The work is labor-intensive, inconsistent, and does not scale across large production environments with multiple species.
At BILLION21, I built the computer vision components of the company's smart aquaculture system. They targeted two tasks that manual observation could not handle consistently: whole-population behavior analysis and individual-level size estimation for olive flounder and stone flounder. Other teams at the company developed the feeding control logic, edge hardware, and feeder mechanisms; my contribution was the vision signals those downstream modules depended on.
YOLO handled population-level behavior detection, tracking movement patterns across the tank to inform feeding decisions. SAM handled individual-level segmentation, producing size estimates for growth monitoring. Both models were tuned for real farm imaging conditions rather than research-grade datasets.
The components were deployed in real production environments and contributed to BILLION21's commercial product development. The operational data such systems generate — feeding logs, growth time series, and environmental sensor traces — is precisely what the DEMETER smart-aquaculture extension (see ongoing applications above) is being built to verify and share across parties.
In Korean laver farming, spores are cultivated in water tanks and implanted onto nets wrapped around rotating frames. Verifying whether enough spores have attached to each net section determines harvest readiness, but this was done entirely by hand and eye, limiting efficiency and consistency across large-scale operations.
This automated spore sorting system uses a camera device (a biological microscope with a mercury lamp) mounted on the harvesting apparatus to photograph spores. Images are transmitted to a central control terminal that measures spore density and decides planting completeness: if the density is above the threshold, the net section is selected for harvest; if below, it is re-cultivated.
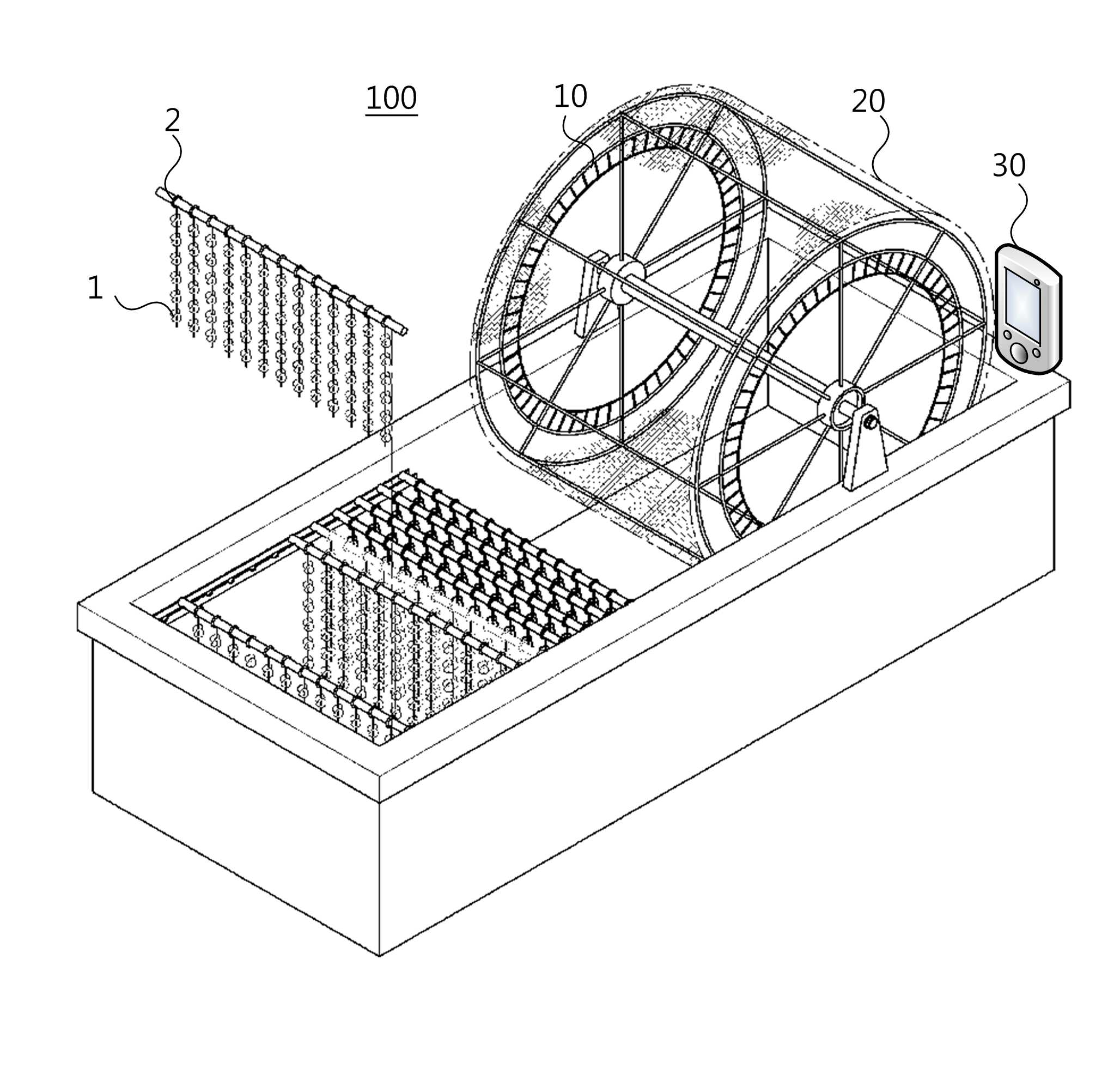
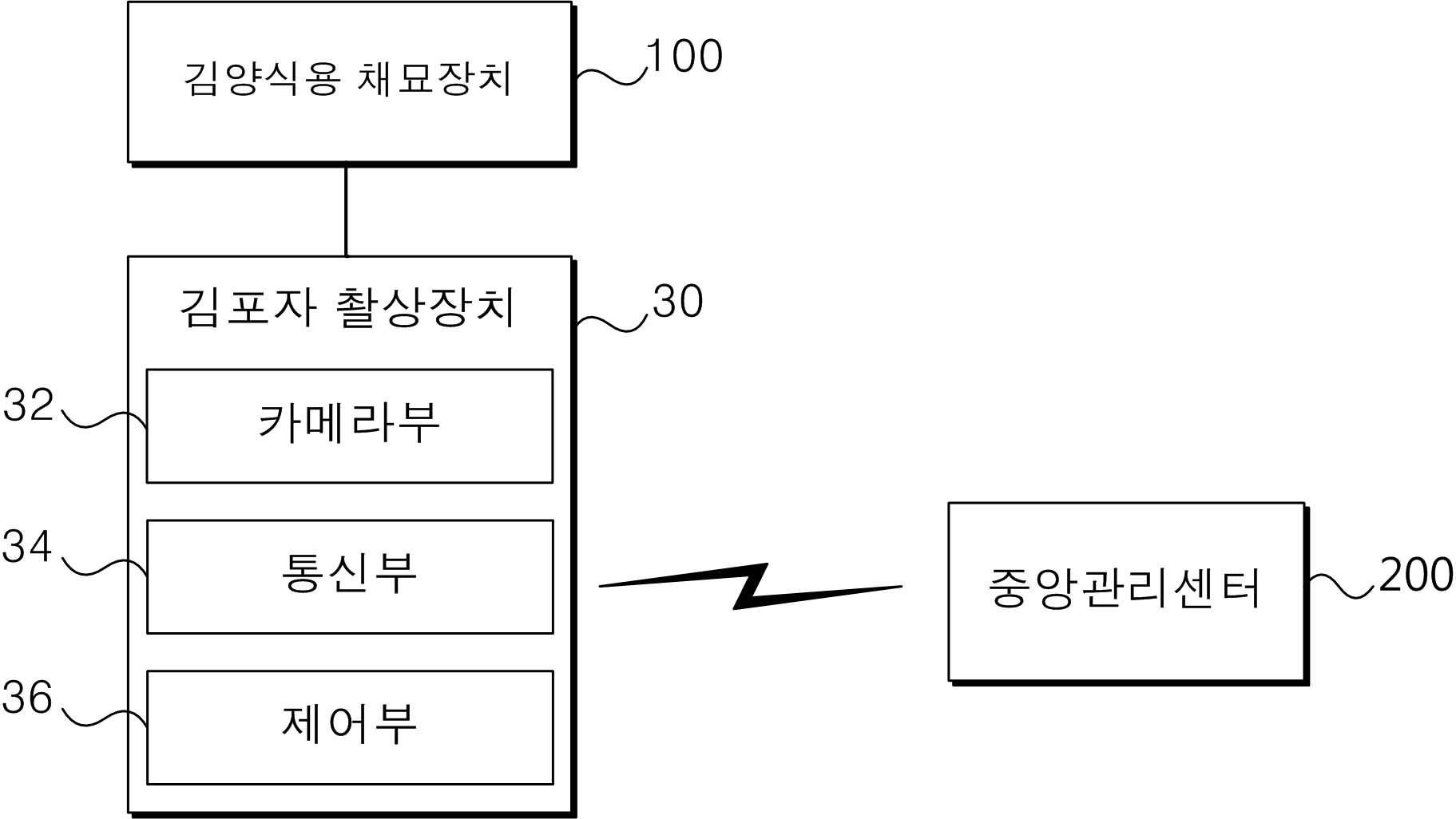
The control center database accumulates image data of completed plantings and builds a machine learning model from that data, automating verification that was previously manual.
Patent KR102034354B1, 2019. Status: Granted. Google Patents
Manual identification of tree trunks in citrus groves slows precision spraying and canopy management. This CNN-based image segmentation pipeline (PyTorch, ABE 6933) was implemented end-to-end from data preparation through training and inference, producing per-trunk masks usable for downstream precision-ag automation.
During undergraduate research at Texas Tech, I applied ML models to real-world datasets across different domains to build hands-on experience with end-to-end pipelines for detection, classification, and recognition tasks across three modalities:
† Equal contribution
Reviewer for 5 journals (2024–Present):
I teach problem-first. I start with a real-world scenario in plain language, then bring in the tools needed to solve it. Students build intuition before they learn the formal methods, and they practice three things in sequence: identifying what is missing, designing what is needed, and testing whether it actually works.
University of Florida · Department of Agricultural and Biological Engineering
Office of Academic Support (OASIS), University of Florida
Coach in the PUSH4IT peer coaching program, helping students develop academic strategies, time management, and goal-setting skills to support on-time graduation.
ABE Mentoring Program, University of Florida
Mentored undergraduate students in data-driven agriculture through the ABE department's peer mentoring program.
Technical blog with 790+ posts covering Python, C/C++, AI, blockchain, and algorithms. Mentoring students on graduate school preparation, career guidance, and coding interview prep.
via Kakao Together
Supporting programs for vulnerable children, youth aging out of foster care, and communities affected by crisis in South Korea.
The same problem DEMETER addresses, tracking what crosses organizational boundaries, applies here. Every visitor to this site connects from somewhere, and each connection is recorded as a node on the map below. The infrastructure mirrors what the projects above describe.
0 connections from 0 countries
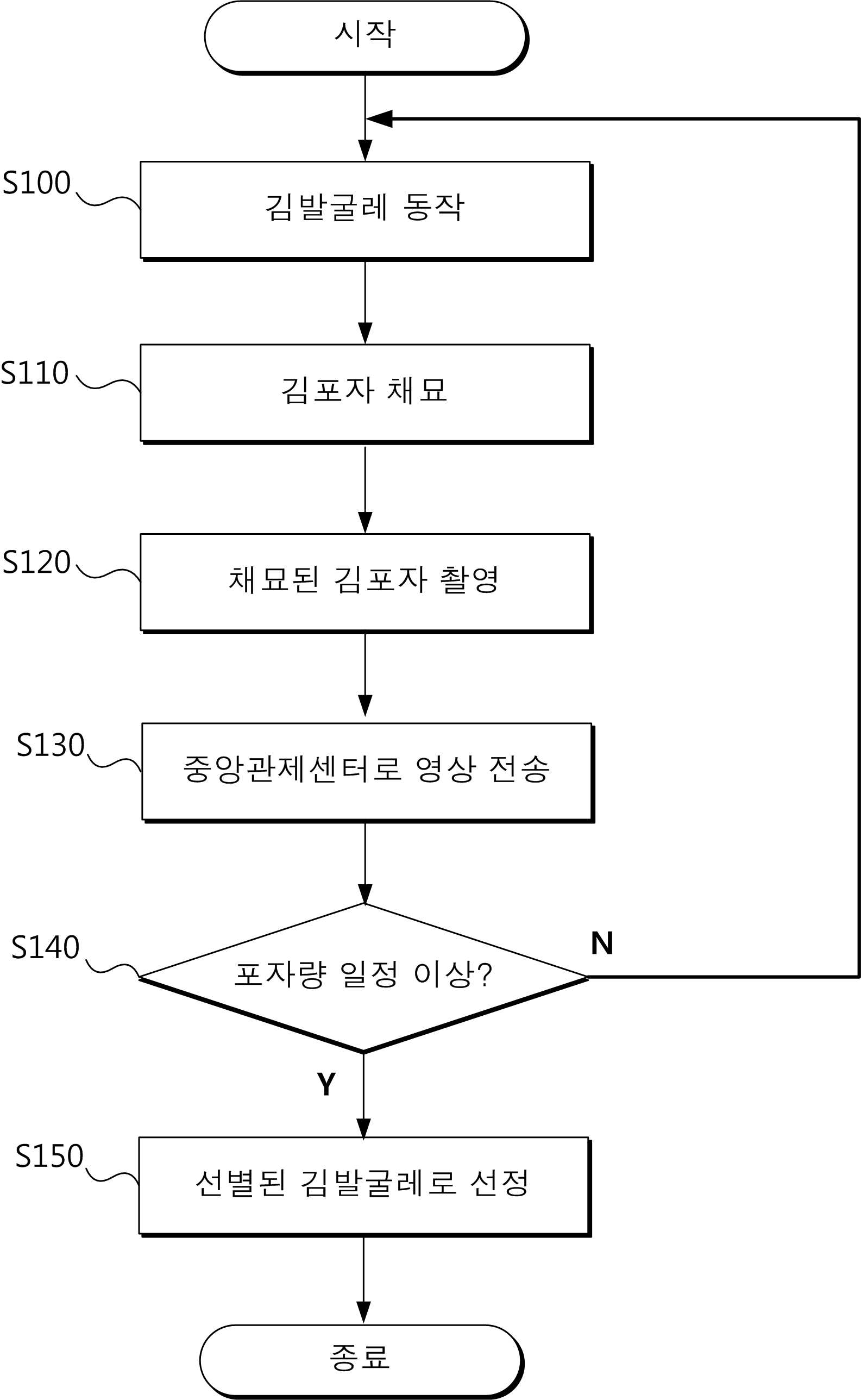
Privacy: only country name and obfuscated coordinates (~30km random offset) are stored. No IP address, city, or personal data is recorded. Each browser submits at most once per 24 hours.